«World of Data – Conceptos Básicos» de Joan Gasull
El objetivo de este artículo es poner un poco de orden y aclarar las distintas vertientes del mundo de los datos. Ciencia de datos, inteligencia de negocio, ingeniería del dato, el famosísimo Big Data… los términos se acumulan, y para una persona ajena al campo, es muy sencillo perderse.
¿Cuál ha sido la solución a este caos de nombres y disciplinas? Big Data. Todo el mundo ha terminado resumiendo este complejo mundo con el concepto comodín. Esto es bastante impreciso, ya que si bien es quizás el termino más general, en muchos casos no hace justicia a la palabra BIG, sino exclusivamente a DATA.
Vamos a repasar las cuatro vertientes principales del mundo de los datos (BI, Data Analytics, Data Science y Data Engineering), ordenadas de menos técnicas a más técnicas, para terminar con los dos conceptos más populares de todos, la IA y el Big Data.
El Business Intelligence es la disciplina basada en datos más clásica. Para entendernos, es aquella que se parece más al trabajo con Excel (de hecho, es totalmente normal encontrar posiciones de BI en Excel). Se fundamenta en la creación de cuadros de comandos –dashboards-, que representan el estado actual o pasado del negocio. Porcentajes de ventas, evoluciones temporales, tablas de productos más vendidos… El rol de analista de negocio es crear este tipo de resúmenes y sacar provecho de ellos, orientando las futuras decisiones.
Algunos de los programas más populares de este campo son PowerBI , Excel o Tableau.
La analítica de datos es quizás la más difícil de definir. Se encuentra en un punto intermedio entre las demás vertientes de datos, y esto hace que podamos encontrar mucha variedad de profesionales, desde los más orientados al código hasta aquellos o aquellas especializados en los programas que acabamos de comentar en el punto anterior. El rol de analista de datos engloba desde la obtención hasta la modelización de datos, pasando por la transformación y el resumen. Es habitual encontrarlo vinculado al concepto insights, que podríamos traducir como claves. La analítica de datos busca claves o comprender mejor los datos para sacar conclusiones que antes no eran evidentes.
A parte de los programas comentados en el punto anterior, es habitual encontrar posiciones de analista con los lenguajes Python, R o también SQL.
La ciencia de datos da un paso más allá que la analítica de datos clásica, y empieza a usar modelos de Machine Learning (aprendizaje automático) para hacer predicciones. La gran diferencia es que ésta está orientada a eventos que aún no han ocurrido, y como podemos usar nuestros datos para anticiparlos. Por ejemplo, el tipo de producto que comprará un cliente al acceder a nuestra web o la probabilidad de sufrir cáncer dadas las características de un paciente. Normalmente se describe como la intersección entre Informática, Estadística y Negocio.
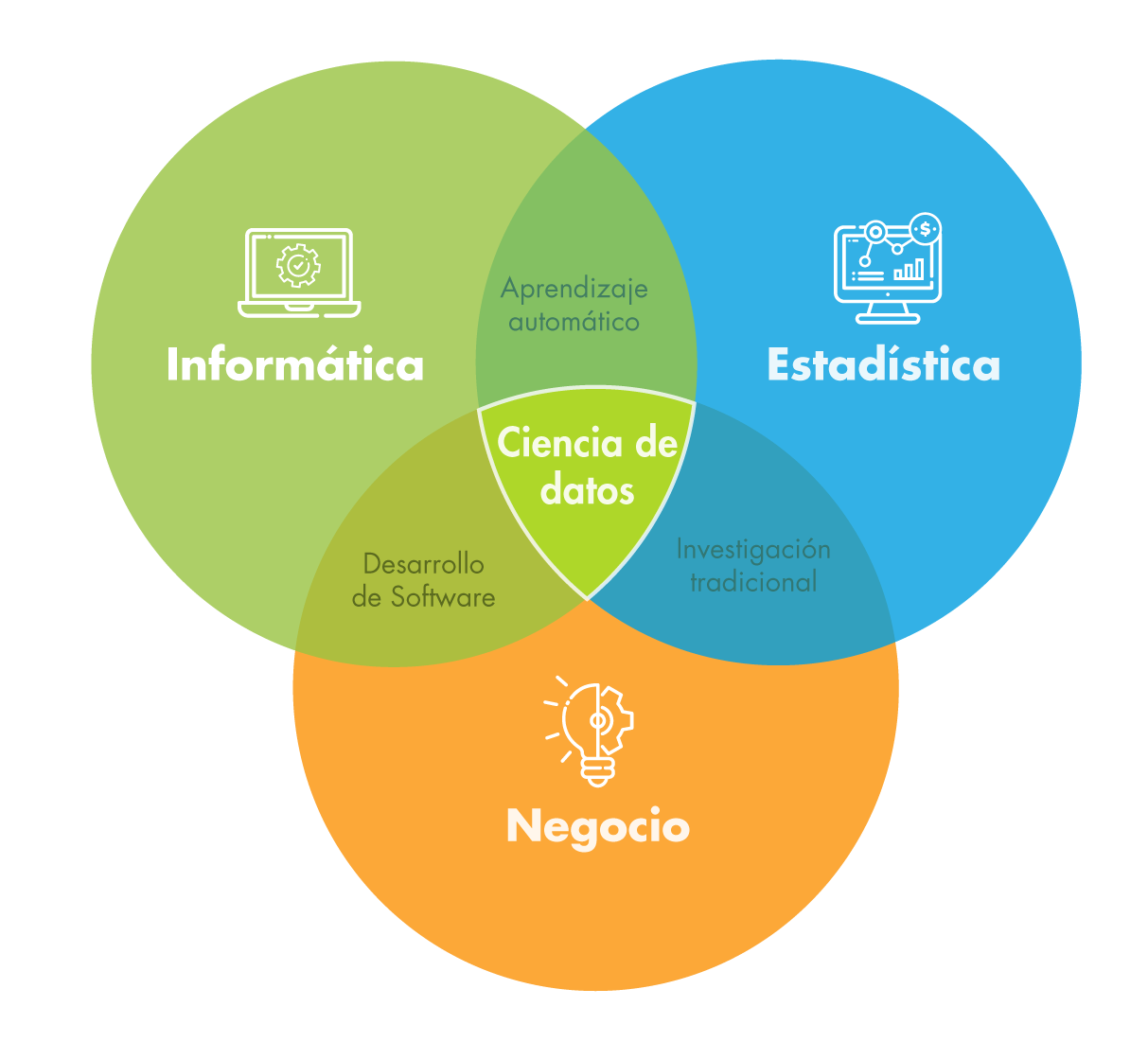
La ciencia de datos está mayoritariamente vinculada a lenguajes de programación, especialmente Python , y en menor medida R o SQL.
La ingeniería de datos es la vertiente más técnica de todas. Más asociada al cómo que no al qué, se fundamenta en los principios de extraer, transformar y cargar (ETL), que no deja de ser un resumen del proceso de mover datos para su posterior explotación. Un o una profesional de la ingeniería de datos se encarga de estructurar las bases de datos o warehouses, asegurando que los datos se almacenan y usan de manera eficiente y segura. Es quizás la dimensión de los datos “menos amable” para usuarios finales, ya que se acerca más a la informática más clásica que a la analítica.
A los ya mencionados Python, R y SQL, habría que añadirle algún lenguaje clásico como Java, o el menos conocido Scala.
Hemos reservado un espacio al final para hablar de los dos conceptos más delicados, no por su poca vigencia (más bien sería al revés), sino por su uso indiscriminado en el discurso público.
El concepto Inteligencia Artificial es bastante complejo de definir, y en muchos casos se abusa de él. En la mayoría de medios de comunicación se usa para describir procesos o algoritmos que en realidad son de Machine Learning. La frontera es un poco borrosa (de hecho, en muchos casos se considera el ML un sub-campo de la IA) pero la diferencia principal entre ambas es que se considera Inteligencia si existe una creatividad o toma de decisiones autónoma, y la enorme mayoría de algoritmos de Machine Learning no hace tal cosa, sino que responde a una tarea muy específica. Un ejemplo de actualidad es esta noticia que apareció en la mayoría de periódicos que detalla una “IA” –en realidad es sería más correcto un modelo de clasificación de Machine Learning- que es capaz de discernir la COVID19 usando el sonido de la tos.
Para el público general, es razonable confundir Machine Learning con Inteligencia Artificial, ya que al fin y al cabo en ambos casos se trata de máquinas que producen resultados autónomamente, pero a nivel técnico, el Machine Learning es un campo con un gran futuro –y presente- en la gran mayoría de negocios, mientras que la Inteligencia Artificial aún está lejos de poder aplicarse a nivel generalizado (los ejemplos más conocidos actualmente son la conducción autónoma o los asistentes de voz).
Y, para terminar, una breve aclaración sobre el Big Data. Éste hace referencia a todos los procesos que hemos estado describiendo en este artículo, cuando necesitamos métodos o tecnologías no convencionales para llevarlos a cabo, ya que los ordenadores particulares, por ejemplo, no tienen suficiente potencia. Comúnmente se hace referencia a un mayor volumen, variedad y velocidad de generación de datos.
Entonces, hablamos de Big Data cuando la cantidad o tipo de datos requiere un tratamiento especial, normalmente en arquitecturas distribuidas en la nube, como Microsoft Azure o Amazon Web Services. Así que, para ser más concretos, es preferible empezar a utilizar expresiones del tipo “soluciones de ciencia de datos en entorno Big Data”, o “Big Data para análisis de negocio”.
